Java Garbage Collector: un’introduzione ai diversi algoritmi
Introduzione
In questo articolo descriviamo una situazione problematica in cui, durante lo sviluppo di un progetto in AIknow, ci siamo imbattuti e che ci ha spinto ad approfondire il funzionamento del Garbage Collector, nonché le differenze tra i diversi algoritmi esistenti per il Garbage Collecting. Infine, vedremo come siamo riusciti a risolvere il problema.
Il caso d’uso
Per un nostro cliente che opera nel settore delle telecomunicazioni, abbiamo realizzato un’applicazione web che implementa la funzionalità di dispatcher per tutte le comunicazioni scambiate all’interno di una rete radio. Il backend, sviluppato in Java, deve essere in grado di elaborare una grande quantità di messaggi quando la rete radio è composta da centinaia o addirittura migliaia di radio (alcune installazioni processano oltre 300 messaggi al minuto). Di conseguenza, l’applicazione consuma grandi quantità di memoria, rendendo necessario un Garbage Collector molto rapido nel liberare lo spazio inutilizzato nell’Heap Space.
Il problema
In situazioni di stress applicativo, abbiamo riscontrato due problemi gravi:
- Eccezione
 : viene lanciata quando l’applicazione tenta di utilizzare più memoria di quella assegnata
: viene lanciata quando l’applicazione tenta di utilizzare più memoria di quella assegnata -
Blocco dell’applicazione: l’applicazione Java rimaneva bloccata per circa 15 secondi, senza produrre log o output.
La nostra indagine
Abbiamo creato un ambiente di test con un dataset simile a quello di produzione, generando heap dump della JVM a intervalli regolari e analizzandoli con Eclipse MAT. Grazie al rilevatore automatico di anomalie di MAT, abbiamo ottenuto grafici come quello mostrato in figura e individuato un memory leak che causava un utilizzo improprio della memoria.
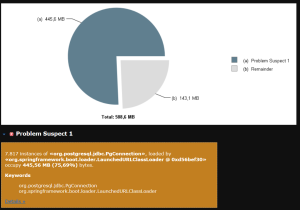
Per quanto riguarda il problema del blocco, era necessario monitorare in tempo reale l’utilizzo della memoria, sperando di rilevare comportamenti anomali durante i blocchi.
Come è strutturato il Java Heap Space
L’Heap Space è la porzione di memoria fisica utilizzata da Java per allocare dinamicamente oggetti e classi durante l’esecuzione dell’applicazione. Il Garbage Collector interviene periodicamente per liberare memoria.
- Young Generation
Qui vengono allocati i nuovi oggetti. Quando questa area si riempie, viene eseguita una minor collection. La Young Generation è ulteriormente suddivisa in Eden Space e Survivor Space. Un oggetto che sopravvive a un certo numero di minor collections viene promosso da Eden a Survivor, e successivamente alla Old Generation. - Old Generation
Contiene gli oggetti con vita più lunga, chiamata anche Tenured Space. Quando questa area si riempie, si avvia una major collection, che ripulisce l’intero Heap. Le major collection sono meno frequenti ma molto più costose dal punto di vista computazionale
L’obiettivo delle Generations è minimizzare la necessità di eseguire major collections.
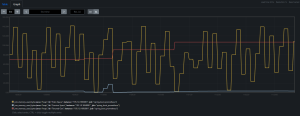
Monitoraggio della memoria Heap in tempo reale
Per monitorare l’utilizzo della memoria heap in tempo reale abbiamo utilizzato Prometheus, uno strumento intuitivo che permette di visualizzare in grafici personalizzati molte metriche prodotte dalla JVM.
- giallo = Young/Eden
- azzurro = Young/Survivor
- rosso = Old/Tenured
Come leggere i log del Garbage Collector
Per confermare la nostra ipotesi, abbiamo attivato i log del Garbage Collector aggiungendo il parametro -verbose:gc al comando di avvio della JVM.
[768327.260s][info][gc] GC(24076) Pause Full (Allocation Failure) 956M->215M(989M) 15921.040ms
![[768327.280s]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-7cd19c9441ff09322f209406fe4c041a_l3.png "Rendered by QuickLaTeX.com") : timestamp da avvio applicazione
: timestamp da avvio applicazione![[info]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-91aad958fbd1d58c718ffb865608a361_l3.png "Rendered by QuickLaTeX.com") : livello di log
: livello di log![[gc]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-e8a4e981d4e3a71de5864a72799bf28e_l3.png "Rendered by QuickLaTeX.com") : indica log del Garbage Collector
: indica log del Garbage Collector : identificativo del GC
: identificativo del GC : tipo di collection (minor o major)
: tipo di collection (minor o major) : causa della collection (normale, indica che la JVM non ha potuto allocare memoria e quindi ha attivato la collection)
: causa della collection (normale, indica che la JVM non ha potuto allocare memoria e quindi ha attivato la collection) : memoria in uso prima e dopo la collection, e dimensione totale dell’heap
: memoria in uso prima e dopo la collection, e dimensione totale dell’heap : durata della collection (circa 15 secondi)
: durata della collection (circa 15 secondi)
Diversi algoritmi di Garbage Collecting
Abbiamo identificato che l’algoritmo usato era il Serial. All’avvio infatti compariva:
[0.034s][info][gc] Using Serial
- il server è multiprocessore, e quindi serve un GC multi-thread
- il dataset è ben più grande di 100 MB
Esistono altri algoritmi multi-thread, come il G1, molto più efficienti. Nel nostro caso, utilizzando il GC G1, anche le major collections (indicate nei log come Concurrent Cycle) venivano eseguite in background e con tempi decisamente inferiori (373 ms contro i circa 15 secondi del Serial):
[1913.644s][info][gc] GC(209) Pause Young (Normal) (G1 Evacuation Pause) 220M->131M(256M) 84.159ms [1915.310s][info][gc] GC(211) Concurrent Cycle [1915.683s][info][gc] GC(211) Concurrent Cycle 372.997ms
Quale algoritmo scegliere per la mia applicazione?
Riassumendo:
- dataset piccoli (fino a 100 MB):

- esecuzione su singolo processore senza vincoli di pausa:
- massima performance senza vincoli di pausa o pause accettabili (≥1s):
 o default
o default - pause inferiori a circa 1 secondo e tempo di risposta prioritario:
 o
o 
- heap molto grandi e priorità alta sul tempo di risposta:

Conclusione
In questo articolo abbiamo spiegato cos’è il Garbage Collector, la struttura della memoria Heap, come attivare e interpretare i log del GC. Abbiamo quindi analizzato un caso reale che ha evidenziato l’importanza di configurare correttamente la JVM scegliendo l’algoritmo di Garbage Collection più adatto alle caratteristiche dell’applicazione Java. Infine, abbiamo illustrato le differenze principali tra i vari algoritmi di Garbage Collecting.
Hai bisogno di supporto per migliorare le prestazioni della tua applicazione Java? contattaci

