Soluzione per la serializzazione e la trasmissione di messaggi su canali a banda limitata
In questo articolo presentiamo una soluzione per la serializzazione di messaggi su un canale a banda limitata che abbiamo implementato all’interno di un progetto. Questo meccanismo si basa sul tool Protocol Buffers, sviluppato da Google.

Il problema
Supponiamo di avere un sistema che prevede lo scambio di pacchetti dati ad alta importanza dal campo verso un’applicazione centralizzata utilizzando canali di comunicazione a banda limitata, dove è possibile inviare al massimo un certo numero di Bytes per ogni pacchetto.
Inoltre, supponiamo che i pacchetti dati scambiati siano di diverso tipo, e che alcune tipologie di messaggi abbiano campi a dimensione variabile, come stringhe di testo.
In questo scenario, è probabile che alcuni messaggi abbiano una lunghezza che supera la dimensione massima inviabile sul canale di comunicazione.
Per essere in grado di inviare tutti i possibili messaggi che vengono composti dal campo o dall’applicazione centralizzata, è fondamentale trovare una modalità di serializzazione che preveda un certo grado di compressione del messaggio e, inoltre, che possa gestire anche il caso in cui il messaggio serializzato abbia comunque una dimensione maggiore del limite di trasmissione.
La soluzione
Per risolvere il problema descritto al punto precedente, abbiamo scelto di utilizzare Protocol Buffers, un tool di serializzazione binaria sviluppato da Google che è in grado di serializzare dati tipizzati e strutturati ottenendo in output un semplice array di byte.
La scelta è ricaduta su questo strumento per una serie di motivi.
Innanzitutto, si tratta di uno strumento open-source sviluppato da Google, moderno e attualmente molto utilizzato in diversi ambiti e applicazioni per la sua grande flessibilità e per la dimensione compatta dell’output, rispetto ad altri meccanismi di serializzazione come JSON.
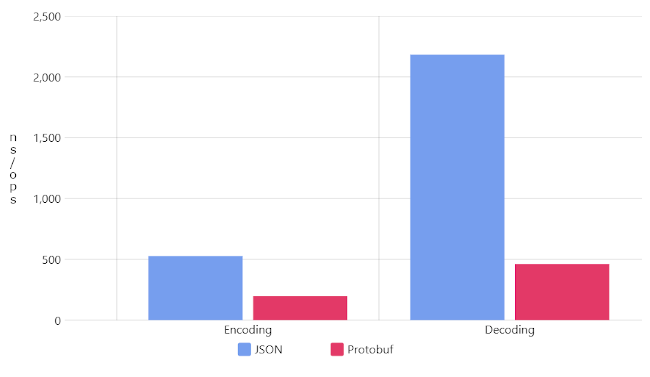
Protocol Buffers offre un metodi di serializzazione/deserializzazione molto più performante rispetto ad altre tecnologie come JSON o altro.
Per fare un esempio, nell’immagine a fianco sono messi a confronto i processi di serializzazione e deserializzazione di un messaggio utilizzando JSON e Protocol Buffers, paragonando il tempo impiegato ad eseguire una singola operazione.
Tra gli altri vantaggi considerati per questa tecnologia, segnaliamo che Protocol Buffers è platform-independent, ed esiste il supporto per una serie di linguaggi diversi come C++, Java, C#, Kotlin, Python, ecc…
Infine, questo meccanismo lavora su dati tipizzati e strutturati, utilizzando classi auto-generate sulla base di file di descrizione che illustrano la struttura di ciascun tipo.
Questi file di descrizione hanno estensione .proto e contengono la dichiarazione del formato di ciascun tipo di messaggio. Sulla base dei file .proto necessari, Protocol Buffers mette a disposizione un compilatore che genera le rispettive classi nei linguaggi supportati.
Esempio
Definizione file .proto di esempio
Supponiamo, ad esempio, di aver bisogno di serializzare con Protocol Buffers una classe Person che contiene alcune informazioni di una persona:
- Nome
- Cognome
- Indirizzo
- Numero di telefono
Il primo step è creare un file Person.proto che descriva questa struttura dati (a fianco).
// Protocol Buffer declaration
syntax = "proto3";
package tutorial;
// Java namespace declaration
option java_package = "com.example.tutorial.protos";
message Person {
uint32 ID = 1;
string NAME = 2;
string SURNAME = 3;
string ADDRESS = 4;
string EMAIL = 5;
string TEL = 6;
}
Come vediamo, è possibile descrivere la struttura dell’oggetto utilizzando una serie di tipi e impostando un’ordinamento/numerazione dei suoi campi. I tipi supportati, così come la sintassi, sono descritti nella documentazione ufficiale.
In particolare, sono dettagliati i tipi di dato messi a disposizione da Protocol Buffers e il riferimento al corrispondente tipo in ciascuno dei linguaggi supportati.
Sono previsti anche campi opzionali, liste, tipi generici ed enumerazioni, annidamento di tipi all’interno di altri tipi di messaggio.
Generazione classi Protocol Buffers
In seguito alla scrittura di un file .proto, lo step successivo per poter utilizzare la classe all’interno di un progetto è la generazione della classe nel linguaggio richiesto. Si deve, quindi:
Scaricare il ProtoBuf compiler dal repository di Protocol Buffers
Lanciare il compilatore indicando il file proto come input, la destinazione del file di output e il linguaggio di destinazione.
Ad esempio, per ottenere una classe Java legata al file Person.proto sopra presentato, è sufficiente lanciare il comando:
protoc -I=$SRC_DIR –java_out=$DST_DIR $SRC_DIR/Person.proto
dove $SRC_DIR indica la cartella base del progetto e –java_out=$DST_DIR specifica di generare una classe nel linguaggio Java e salvarla nel path $DST_DIR.
Serializzazione e dimensione ridotta della trasmissione
Ritornando al problema illustrato all’inizio dell’articolo, però, l’uso di Protocol Buffers (così come di qualsiasi altro processo di serializzazione) non risolve il vincolo relativo alla dimensione massima inviabile per ciascun messaggio.
Per questo motivo si è reso necessario pensare a un meccanismo che sfruttasse Protocol Buffer per la serializzazione, ma che prevedesse anche operazioni di frammentizzazione e ricostruzione di un singolo messaggio in più blocchi che possano rispettare i limiti di trasmissione imposti dalla tecnologia.
Abbiamo, quindi, pensato a questa soluzione, dove un singolo messaggio viene spezzato in tanti frammenti sulla base della dimensione massima inviabile sul canale e tenendo conto di un numero di bytes di header aggiunti a ciascun pacchetto..
Contenuto dei byte di header
Questi byte di header sono necessari perché il messaggio, una volta frammentato, deve anche essere ricostruito dall’altra parte, e per questa operazione sono necessarie una serie di informazioni utili alla ricostruzione e al riconoscimento di questi particolari pacchetti.
- Le informazioni che abbiamo previsto sono:
- Una serie di caratteri speciali ASCII come iniziatori di ciascun pacchetto, utilizzati per discriminare questi pacchetti da altre comunicazioni inviate,
- Un ID incrementale che raggruppa tutti i frammenti che fanno parte di un singolo messaggio,
- La lunghezza del body del frammento in bytes,
- Il numero del singolo frammenti (nel caso di frammentazione in N pacchetti, da 0 a N-1),
- Il numero totale di frammenti,
- La classe di riferimento del messaggio che è stato serializzato tramite Protocol Buffers.

Una delle sfide riscontrate nella definizione di questo protocollo è stata la scelta di come utilizzare i byte di header, al fine di ridurre il più possibile il numero di Bytes riservati a immagazzinare queste informazioni accessorie.
Allo stesso tempo, i Bytes di header devono essere sufficientemente capienti per garantire la possibilità di frammentare messaggi di tipi diversi senza avere vincoli troppo stringenti sul numero di frammenti massimi che è possibile creare.
Considerazioni
Attraverso questo procedimento siamo stati in grado di trasmettere informazioni a lunghezza variabile su un canale di comunicazione con vincoli sulla dimensione massima del payload.
Utilizzando Protocol Buffers siamo stati in grado di eseguire operazioni di serializzazione performanti e ottimizzate mantenendo il livello di astrazione offerto dai file .proto di descrizione.
Infine, attraverso il nostro meccanismo di frammentazione abbiamo superato il vincolo sulla dimensione massima trasmissibile sul canale di comunicazione.
Casi d'uso
Abbiamo utilizzato questo sistema per lo scambio di messaggi tra dispositivi Android sul campo e un’applicazione .NET Core in cloud che comunicano attraverso una rete radio TETRA.
TETRA – TErrestrial Trunked RAdio – è un sistema radio cellulare professionale bidirezionale standardizzato da ETSI.
La tecnologia TETRA è stata specificatamente progettata per l’utilizzo da parte delle amministrazioni pubbliche, servizi di emergenza, (forze di polizia, vigili del fuoco, servizi sanitari, ecc.) per le reti di pubblica sicurezza, per il personale del trasporto ferroviario e degli aeroporti e per servizi militari.
Dal momento che si propongono a queste tipologie di utenti, le reti TETRA forniscono un alto livello di affidabilità e una serie di modalità di connessione per coprire il maggior numero di situazioni, inclusa una Direct Mode che consente a più apparati radio di comunicare tra di loro anche in caso di guasti all’infrastruttura.
Nello specifico, la rete radio TETRA con la quale ci siamo interfacciati limita la dimensione dei messaggi scambiati a un massimo di 255 byte. Poiché l’obiettivo era far transitare diverse tipologie di messaggi con una dimensione maggiore, abbiamo utilizzato questo sistema di serializzazione, riscontrandone con successo le prestazioni e l’efficacia.

