Java Garbage Collector: introducción a los distintos algoritmos
Introducción
En este artículo describimos una situación problemática con la que nos encontramos durante el desarrollo de un proyecto en AIknow, y que nos impulsó a analizar en profundidad el funcionamiento del Recolector de Basura, así como las diferencias entre los distintos algoritmos existentes para la Garbage Collecting. Por último, veremos cómo conseguimos resolver el problema.
El caso práctico
Para un cliente nuestro que opera en el sector de las telecomunicaciones, desarrollamos una aplicación web que implementa la funcionalidad de despachador para todas las comunicaciones intercambiadas dentro de una red de radio. El backend, desarrollado en Java, debe ser capaz de procesar una gran cantidad de mensajes cuando la red de radio está formada por cientos o incluso miles de radios (algunas instalaciones procesan más de 300 mensajes por minuto). Por consiguiente, la aplicación consume grandes cantidades de memoria, lo que hace necesario un recolector de basura que sea muy rápido a la hora de liberar el espacio no utilizado en el espacio Heap.
El problema
En situaciones de estrés de aplicación, nos encontramos con dos problemas graves:
 : se lanza cuando la aplicación intenta utilizar más memoria de la asignada
: se lanza cuando la aplicación intenta utilizar más memoria de la asignada-
Congelación de la aplicación: La aplicación Java permaneció bloqueada durante unos 15 segundos, sin producir ningún registro ni salida.
Nuestra investigación
Creamos un entorno de pruebas con un conjunto de datos similar al de producción, generando volcados de memoria heap de la JVM a intervalos regulares y analizándolos con Eclipse MAT. Gracias al detector automático de anomalías de MAT, obtuvimos gráficos como el que se muestra en la figura y detectamos una memory leak que provocaba una utilización inadecuada de la misma.
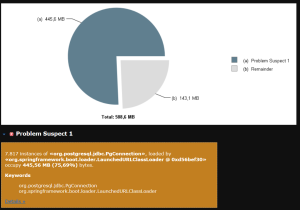
En cuanto al problema de los bloqueos, fue necesario supervisar la utilización de la memoria en tiempo real, con la esperanza de detectar comportamientos anómalos durante los bloqueos.
Cómo se estructura el espacio Heap de Java
El espacio de montón es la porción de memoria física utilizada por Java para asignar dinámicamente objetos y clases durante la ejecución de la aplicación. El recolector de basura interviene periódicamente para liberar memoria.
- Young Generation
Aquí se asignan los nuevos objetos. Cuando esta zona se llena, se realiza una minor collection. La Generación Joven se divide a su vez en Eden Spage e Survivor Space. Un objeto que sobrevive a un cierto número de recolecciones menores es promovido de Edén a Superviviente, y luego a Generación Antigua. - Old Generation
Contiene los objetos más longevos, también llamados Tenured Space. Cuando este espacio se llena, se inicia una major collection, que limpia todo el montón. Las recolecciones mayores son menos frecuentes pero mucho más costosas desde el punto de vista computacional.
El objetivo de Generaciones es minimizar la necesidad de realizar grandes recogidas.
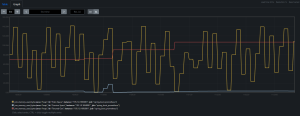
Supervisión de la memoria Heap en tiempo real
Para supervisar la utilización de la memoria de montón en tiempo real, utilizamos Prometheus, una herramienta intuitiva que permite visualizar muchas métricas producidas por la JVM en gráficos personalizados.
- Amarillo = Young/Eden
- Azul claro = Young/Survivor
- Rojo = Old/Tenured
Cómo leer los registros del Recolector de Basura
Para confirmar nuestra hipótesis, activamos los registros del Recolector de Basura añadiendo el parámetro -verbose:gc al comando start de la JVM.
[768327.260s][info][gc] GC(24076) Pause Full (Allocation Failure) 956M->215M(989M) 15921.040ms
![[768327.280s]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-7cd19c9441ff09322f209406fe4c041a_l3.png "Rendered by QuickLaTeX.com") : marca de tiempo del inicio de la aplicación
: marca de tiempo del inicio de la aplicación![[info]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-91aad958fbd1d58c718ffb865608a361_l3.png "Rendered by QuickLaTeX.com") : nivel de registro
: nivel de registro![[gc]](https://www.aiknow.io/wpvt/wp-content/ql-cache/quicklatex.com-e8a4e981d4e3a71de5864a72799bf28e_l3.png "Rendered by QuickLaTeX.com") : indica el registro del recolector de basura.
: indica el registro del recolector de basura. : Identificador GC
: Identificador GC : tipo de colección (menor o mayor)
: tipo de colección (menor o mayor) : causa de la recolección (normal, indica que la JVM no pudo asignar memoria y por eso activó la recolección)
: causa de la recolección (normal, indica que la JVM no pudo asignar memoria y por eso activó la recolección) : memoria en uso antes y después de la recogida, y tamaño total del montón
: memoria en uso antes y después de la recogida, y tamaño total del montón : duración de la recogida (aprox. 15 segundos)
: duración de la recogida (aprox. 15 segundos)
Varios algoritmos de recogida de basura
Identificamos que el algoritmo utilizado era Serial. En la puesta en marcha, de hecho, apareció:
[0.034s][info][gc] Using Serial
- el servidor es multiprocesador, por lo que se necesita un GC multihilo
- el conjunto de datos es muy superior a 100 MB
Existen otros algoritmos multihilo, como el G1, que son mucho más eficientes. En nuestro caso, utilizando el GC G1, incluso las colecciones más importantes (denominadas en los registros Ciclo concurrente) se ejecutaron en segundo plano y en tiempos mucho más cortos (373 ms frente a los cerca de 15 segundos de Serial):
[1913.644s][info][gc] GC(209) Pause Young (Normal) (G1 Evacuation Pause) 220M->131M(256M) 84.159ms [1915.310s][info][gc] GC(211) Concurrent Cycle [1915.683s][info][gc] GC(211) Concurrent Cycle 372.997ms
¿Qué algoritmo debo elegir para mi aplicación?
En resumen:
- conjuntos de datos pequeños (hasta 100 MB):

- ejecución en un solo procesador sin restricciones de pausa:
- máximo rendimiento sin restricciones de pausa o pausas aceptables (≥1s):
 o por defecto.
o por defecto. - pausas inferiores a 1 segundo aproximadamente y tiempo de respuesta prioritario:
 o
o 
- heaps muy grandes y alta prioridad en el tiempo de respuesta:

Conclusión
En este artículo hemos explicado qué es el Garbage Collector, la estructura de la memoria Heap y cómo activar e interpretar los logs del GC. A continuación, analizamos un caso real que ponía de manifiesto la importancia de configurar correctamente la JVM eligiendo el algoritmo de Garbage Collection más adecuado a las características de la aplicación Java. Por último, ilustramos las principales diferencias entre los distintos algoritmos de Garbage Collection.
¿Necesita ayuda para mejorar el rendimiento de su aplicación Java? Contáctenos

